Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Hadoop components
Hadoop is divided into two core components
- HDFS: a distributed file system;
- YARN: a cluster resource management technology.
HDFS
HDFS, Hadoop Distributed File System, is a filesystem writen in Java, based on Google's GFS. It sits on top of native filesystem (such as ext3, ext4 or xfs), and provides redundant storage for massive amounts of data.
HDFS is optimized for large, streaming reads of files, rather than random reads. Files in HDFS are 'write once' and no random writes to files are allowed.
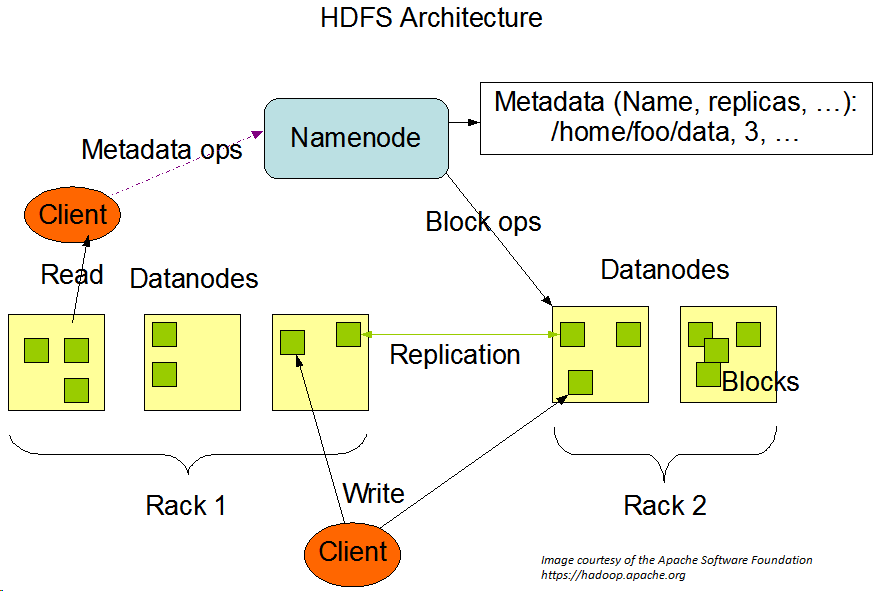
An HDFS cluster has two types of nodes operating in a master−worker pattern: a namenode (the master) and a number of datanodes (workers).
1- Namenode: the master daemon process responsible for managing the file system namespace (filenames, permissions and ownership, last modification date, etc.) and controlling access to data stored in HDFS. It is the one place where there is a full overview of the distributed file system. It maintains the filesystem tree and the metadata for all the files and directories in the tree. This information is stored persistently on the local disk in the form of two files: the namespace image and the edit log. The namenode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to datanodes and also knows the datanodes on which all the blocks for a given file are located. The namenode daemon must be running at all times: if the namenode stops, the cluster becomes inaccesible.
2- Datanodes: slave processes that take care of storing and serving data. A datanode is installed on each worker node in the cluster. Data files are split into 128MB blocks which are distributed at load time. Each block is replicated on multiple datanodes (default 3x). The datanodes are responsible for serving read and write requests from the file system’s clients. The datanodes also perform block creation, deletion, and replication upon instruction from the NameNode.
YARN
YARN, Yet Another Resource Negotiator, is a framework that manages resources on the cluster and enables running various distributed applications that process data stored (usually) on HDFS. The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM).
YARN, similarly to HDFS, follows the master-slave design with single ResourceManager daemon and multiple NodeManagers daemons. The ResourceManager and the NodeManager form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler.
The ResourceManager has two main components: Scheduler and ApplicationsManager. The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The ApplicationsManager is responsible for accepting job-submissions, negotiating the first container for executing the application specific ApplicationMaster and provides the service for restarting the ApplicationMaster container on failure.
You can get more information here
YARN is basically a resource manager that knows how to allocate distributed compute resources to various applications running on a Hadoop cluster. Some of these applications or distributed computation frameworks are MapReduce, Apache Spark, Apache Storm or Cloudera Impala.
Sometimes, YARN is called MapReduce v2.
MapReduce
MapReduce is a programming model for processing large data sets with a parallel, distributed algorithm on a cluster. Apache MapReduce was derived from Google MapReduce: Simplified Data Processing on Large Clusters paper. The current Apache MapReduce version is built over Apache YARN Framework. Basically in this paradigm you provide the logic for two functions: map() and reduce() that operate on pairs.
Map function takes a pair and produces zero or more intermediate pairs. The main purpose of this function is to transform or filter the input data.
Reduce function takes a key and list of list values associated with this key and pruduces zero or more final pairs.
Between map and reduce functions you can shuffle and/or sort by key all the intermediate pairs produced by map function, so that all the values associated with the same key are grouped together and passed to the reduce function.
The following image shows this process.
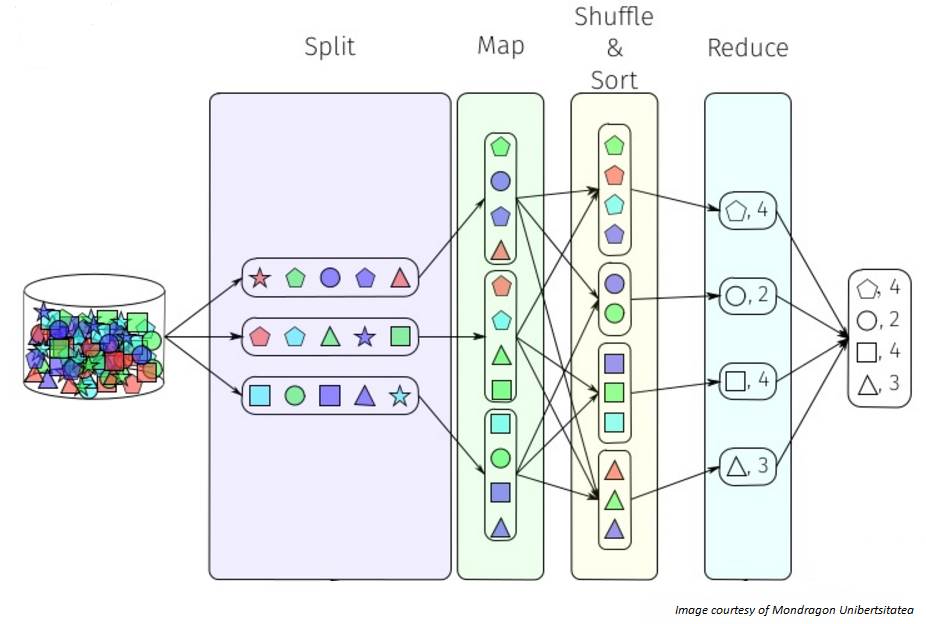
In the picture above you can see the MapReduce process as a 5-step parallel and distributed computation:
- Prepare the map input splitting data
- Run the user-provided map code
- Shuffle and/or sort the Map output to the reduce processors
- Run the user-provided reduce code
- Produce the final output
Hadoop Ecosystem
The Hadoop ecosystem comprises of a lot of sub-projects and we can configure these projects as we need in a Hadoop cluster. Hadoop has come to refer a collection of additional software packages such as Apache Pig, Apache Hive, Apache HBase, Apache ZooKeeper, Apache Flume, Apache Sqoop or Apache Oozie.
The following illustration shows some of the components of the ecosystem of Hadoop.
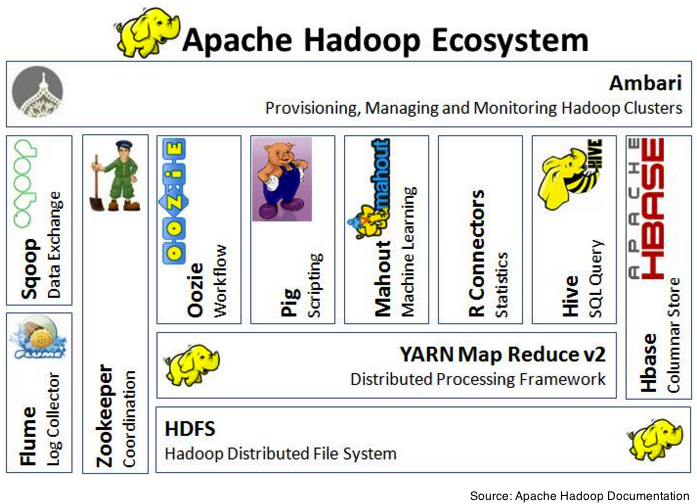
- Flume: Service for aggregating, collecting and moving large amounts of log data.
- Sqoop: Tool for efficient transfer bulk data between Hadoop and structured datastores such as relational databases.
- Zookeeper: Framework that enables highly reliable distributed coordination.
- Oozie: Workflow scheduler system for MapReduce jobs using DAGs (Direct Acyclical Graphs). Oozie Coordinator can trigger jobs by time (frequency) and data availability
- Pig: Pig provides an engine for executing data flows in parallel on Hadoop. It includes a language, Pig Latin, for expressing these data flows. Pig uses MapReduce to execute all of its data processing.
- Hive: Data Warehouse infrastructure developed by Facebook. Data summarization, query, and analysis. It’s provides SQL-like language (not SQL92 compliant): HiveQL.
- HBase: Non-relational, distributed database running on top of HDFS. It enables random realtime read/write access to your Big Data.
- Ambari: Intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs. Apache Ambari was donated by Hortonworks team.
You can get a more complete table of the Hadoop ecosystem at hadoopecosystemtable.github.io.
Hadoop distributions
You can get a list of Hadoop distributions here.
Some of the distributions you can test on your own computer using virtual machines are:
Related posts
Basic ideas about Apache Spark
You can get more information at the following links: