Apache Spark is a fast and general engine for large scale data processing. It is written in Scala, a functional programming language that runs in a JVM. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. You can use Spark through Spark Shell for learning or data exploration (in Scala or Python, and since 1.4, in R) or through Spark Applications, for large scale data processing (mainly in Python, Scala or Java).
The Spark Shell provides interactive data exploration (REPL - Read/Evaluate/Print Loop). You can start Python Shell with pyspark command and Scala Shell with spark-shell command.
Example of starting pyspark on a Cloudera distribution:
and starting with spark-shell
Resilient Distributed Dataset
The fundamental unit of data in Spark are RDDs (Resilient Distributed Dataset). They are resilient because if data memory is lost, it can be recreated; they are distributed because data is stored in memory across the cluster. Initial data of dataset can come from a file or be created programmatically.
There are three ways to create and RDD:
- From a file of set of siles: sc.textFiles("myfile1.txt, myfile2.txt")
- From data in memory
- From another RDD
A RDD is an immutuable distributed collection of data, which is partitioned across machines in a cluster. Most Spark programming consists of performing operations on RDDs . There are two types of operations:
- Actions: An action is an operation such as count(), take(n), collect(), savesAsTextFile(filename) or first() that triggers a computations, returns a value o back to the Master or writes to a stable storage system.
- Transformations: A transformation is an operations such as filter(), map() or union() on a RDD that yields another RDD. They are lazily evaluated, because data in RDDs is not processed until an action operation is performed. RDD is materialized in memmory upon the first action that uses it. Transformations may be chaining together, that is, you can chain several tranformation command joining them by dots, all of them, in a unique big command.
Functional programming in Spark
Spark depends heavily on the concepts of functional programming, where functions are the fundamental unit of programming. Functions have input and output only, no state or side effects. Many RDD operations take functions as parameters. A typical pseudocode for a RDD operation, for example, the map operation is:
RDD {
map(fn(x)) {
foreach record[{ loading ... }]d in rdd
emit fn(record)
}
}
Functions are defined in line without an identifier. This is suppoerted in many programming languages as Scala, Python or Java 8. For example: Python
> mydata.map(lambda line: line.upper()).take(2)
Scala
> mydata.map(line => line.toUpperCase()).take(2)
OR
> mydata.map(\_.toUpperCase()).take(2)
Java 8
...
JavaRDD<String> lines = sc.textFile("file");
JavaRDD<String> lines\_uc = lines.map(
line -> line.toUpperCase());
Executions on Spark
The following illustration summarizes the terminilogy of Sparks on Job executions. 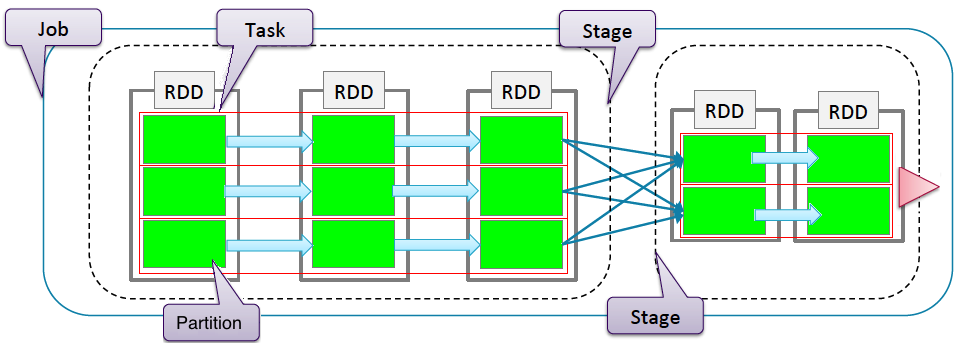
A job is a set of tasks executed as result of an action. A stage is a set of tasks in a job that can be executed in parallel. A task is an individual unit of work sent to one executor over a sequences of partitions. RDD operations are executed in paralell on each partition. When possible, task execute on the worker nodes where the data is in memory. Some operations, such as map, flatmap or filter, preserve partitioning and other operations repartition, such as reduce, sort or group.
Operations that can run on the same partition are executed in stages. Task within a stage are pipelined together. There are two types of operations:
- Narrow operations: Only one child depends on the RDD. These operations like map, filter or union, can operate on a single partition and map the data of that partition to resulting single partition. This means the task can be executed locally and we don’t have to shuffle.
- Wide operations: Multiple children depend on the RDD and a new stage is defined. This means we have to shuffle data unless the parents are hash-partitioned. These operations like groupByKey, distinct or join may require to map the data across the partitions in new RDD. They are considered to be more costly than narrow operations due to data shuffling.
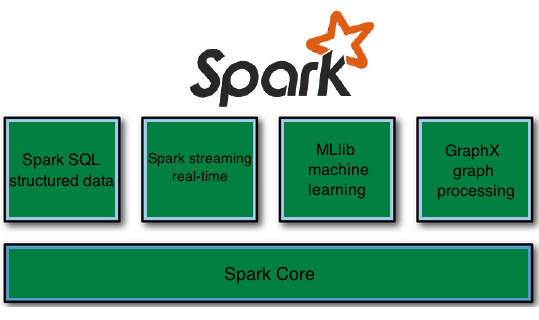
Components of Spark
The following illustration depicts the different components of Spark.
Spark SQL
Spark SQL provides a convenient way to run interactive queries over large data sets using Spark Engine, base on a special type of RDD called SchemaRDD. SchemaRDD has been renamed to DataFrame. A DataFrame is a distributed collection of data organized into named columns; it is similar to a table in RDBMs. DataFrames can be converted to RDDs by calling the rdd method which returns the content of the DataFrame as an RDD of Rows. Data sources for DataFrames can be external databases, hive tables, existing RDDs, JSON datasets or structured data files.
Spark SQL provides two types of contexts: SQLContext and HiveContext that extend SparkContext functionality. SQLContext encapsulates all relational functionality in Spark. It is a simple SQL parser. HiveContext provides a superset of the functionality provided by SQLContext. It can be used to write queries using the HiveQL parser and read data from Hive tables. You don't need an existing Hive environment to use the HiveContext in Spark programs.
Spark streaming
Spark streaming is an extension of core Spark that provides real-time processing of stream data. Support Sacala, Java and Python. It divides up data stream into batches of n seconds and processes each batch as an RDD. The results of RDD operations are returned in batches. Spark streaming uses DStreams, Discritized Stream. A DStream is a sequence of RDDs representing a data stream. Each RDD contains data received in a configurable interval of time. DStreams are created by StreamingContext in a similar way to how how RDDs are created by SparkContext. DStreams are defined for a given input stream, for example, Unix socket. They are also prepared out of the box for other networks sources such as Flume, Akka Actors, Twitter, Kafka, ZeroMQ, etc. and for monitoring folders and files (for example, new files in a directory).
DStream operations are applied to every RDD in the stream. They are executed once per duration. There are two types of DStream operations:
- Transformations: create a new DStream from an existing one.
- Output operations: write data, for example to a HDFS file system, database, other applications, dashboards, and so on. They are similar to RDD actions.
MLib machine learning
Machine learning aims to extract knowledge from data, relying on fundamental concepts in computer science, statistics, probability and optimization. Machine Learning refers to programs that leverage collected data to drive future program behavior. There are three well-established categories of techniques for exploiting data (the three c's):
- Collaborative filtering (recommendations)
- Clustering
- Classification
MLlib is part of Apache Spark and includes many common ML functions:
- Logistic Regression
- Linear Regression
- Gradient Descent
- ALS (alternating least squares)
- k-means
GraphX graph processing
GraphX unifies optimized graph computation with Spark’s fast data parallelism and interactive abilities. GraphX unifies ETL, exploratory analysis, and iterative graph computation within a single system. You can view the same data as both graphs and collections, transform and join graphs with RDDs efficiently, and write custom iterative graph algorithms. You can use GraphX for problems on the relationships between the individual data items. For example, social networks, web page hyperlinks and roadmaps. These relationships can be represented by graphs .
Related posts
You can get more information about Spark at http://spark.apache.org/